Unlock the full potential of cloud data integration with Azure Data Factory—a game-changing service that simplifies how businesses move, transform, and orchestrate data at scale. Whether you’re building ETL pipelines or automating complex workflows, this guide dives deep into everything you need to know.




What Is Azure Data Factory?

Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service that enables organizations to create data-driven workflows for orchestrating and automating data movement and transformation. It plays a pivotal role in modern data architectures, especially within the Azure ecosystem. Unlike traditional on-premises ETL (Extract, Transform, Load) tools, ADF operates entirely in the cloud, allowing seamless integration across hybrid and multi-cloud environments.
Core Purpose and Vision
The primary goal of Azure Data Factory is to enable businesses to build scalable, reliable, and maintainable data pipelines without managing infrastructure. It abstracts away the complexity of data integration by offering a serverless execution model. This means users can focus on defining data workflows rather than provisioning servers or managing clusters.
- Enables hybrid data integration across cloud and on-premises sources
- Supports both code-based and visual pipeline design
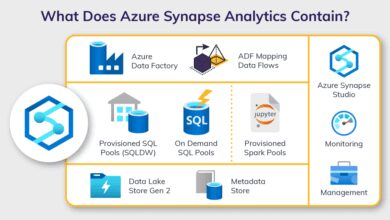
- Integrates natively with other Azure services like Azure Synapse Analytics, Azure Databricks, and Azure Blob Storage
According to Microsoft, ADF is designed to help enterprises “democratize data integration” by making it accessible to both technical and non-technical users through its intuitive interface and rich set of connectors.
How It Fits Into the Modern Data Stack
In today’s data-driven world, organizations collect data from countless sources—CRM systems, IoT devices, social media platforms, and more. Azure Data Factory acts as the central nervous system that connects these disparate sources, transforms raw data into usable formats, and delivers it to analytical systems like data warehouses or machine learning models.
“Azure Data Factory is not just an ETL tool—it’s a complete orchestration engine for your data lifecycle.” — Microsoft Azure Documentation
Its ability to schedule, monitor, and manage data workflows makes it indispensable in modern data engineering practices. With native support for big data processing frameworks and serverless compute options, ADF empowers teams to handle petabyte-scale data operations efficiently.
Key Components of Azure Data Factory
To fully understand how Azure Data Factory works, it’s essential to explore its core components. These building blocks form the foundation of every data pipeline and determine how data flows from source to destination.
Linked Services
Linked services in Azure Data Factory are analogous to connection strings. They define the connection information needed to connect to external resources such as databases, storage accounts, or web services. Each linked service specifies the type of resource, authentication method, and endpoint URL.
- Examples include Azure SQL Database, Amazon S3, Salesforce, and FTP servers
- Supports various authentication types: key-based, OAuth, managed identity, and service principals
- Can be encrypted and stored securely using Azure Key Vault integration
For instance, if you want to extract data from an on-premises SQL Server and load it into Azure Data Lake Storage, you would create two linked services—one for the SQL Server (using the Self-Hosted Integration Runtime) and another for the Data Lake.
Datasets and Data Flows
Datasets represent structured data within your data stores. They don’t hold the data themselves but describe the structure and location of data used in activities. For example, a dataset might point to a specific table in a SQL database or a folder in Azure Blob Storage.
- Datasets are schema-aware and can infer structure from source data
- Used as inputs and outputs in pipeline activities
- Support both static and dynamic paths using parameters
Data flows, on the other hand, are a visual way to define data transformations using a drag-and-drop interface. Built on Apache Spark, they allow you to perform complex transformations like filtering, joining, aggregating, and cleansing without writing code.
“Data flows eliminate the need for manual Spark scripting, making transformation logic accessible to analysts and developers alike.” — Azure Data Factory Team
Pipelines and Activities
A pipeline in Azure Data Factory is a logical grouping of activities that perform a specific task. Activities are the individual steps within a pipeline, such as copying data, executing a stored procedure, or running a Databricks notebook.
- Copy Activity: Moves data between supported data stores
- Lookup Activity: Retrieves data from a source for use in subsequent activities
- Web Activity: Calls REST APIs to trigger external processes
- Execute Pipeline Activity: Enables modular pipeline design by calling other pipelines
Pipelines can be scheduled to run on a timer, triggered by events (like a new file arriving in a blob container), or executed manually. This flexibility makes ADF ideal for both batch and real-time data processing scenarios.
Why Choose Azure Data Factory Over Other Tools?
With numerous data integration tools available—such as Informatica, Talend, AWS Glue, and Google Cloud Dataflow—why should organizations choose Azure Data Factory? The answer lies in its deep integration with the Microsoft ecosystem, scalability, and ease of use.
Seamless Integration with Azure Services
One of the biggest advantages of Azure Data Factory is its native integration with other Azure services. Whether you’re moving data into Azure Synapse Analytics for enterprise data warehousing or triggering Azure Functions for custom logic, ADF provides pre-built connectors and templates that reduce development time.
- Direct integration with Azure Logic Apps for workflow automation
- Support for Azure Databricks for advanced analytics and ML workloads
- Native connectivity to Power BI for real-time reporting
This tight coupling reduces latency and improves performance, especially when all components reside within the same cloud region. You can also leverage Azure Monitor and Azure Log Analytics to gain insights into pipeline performance and troubleshoot issues.
Serverless Architecture and Cost Efficiency
Unlike traditional ETL tools that require dedicated servers or virtual machines, Azure Data Factory uses a serverless compute model. This means you only pay for the resources consumed during pipeline execution, not for idle time.
- No need to provision or manage infrastructure
- Auto-scaling based on workload demands
- Cost-effective for intermittent or bursty workloads
For example, if you run a nightly ETL job that takes 30 minutes, you’re only billed for those 30 minutes of execution. This pay-per-use model is particularly beneficial for startups and mid-sized companies looking to optimize cloud spending.
Hybrid and Multi-Cloud Capabilities
Azure Data Factory supports hybrid data scenarios through the Self-Hosted Integration Runtime (SHIR). This component allows secure data transfer between on-premises systems and the cloud without exposing internal networks to public internet traffic.
- SHIR can be installed on Windows machines inside your corporate firewall
- Supports high availability and load balancing across multiple nodes
- Enables data movement from legacy systems like SAP, Oracle, or mainframes
Additionally, ADF can integrate with non-Azure clouds via REST APIs or third-party connectors, making it a viable option for multi-cloud strategies.
Building Your First Pipeline in Azure Data Factory
Creating a pipeline in Azure Data Factory is a straightforward process, thanks to its intuitive user interface and guided experiences. Let’s walk through the steps to build a simple ETL pipeline that copies data from Azure Blob Storage to Azure SQL Database.
Step 1: Create a Data Factory Instance
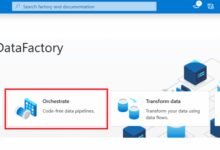
Log in to the Azure Portal, navigate to the “Create a resource” section, and search for “Data Factory.” Select the service, choose a subscription, resource group, and region, then click “Create.” Once deployed, open the Data Factory studio to begin designing your pipeline.
- Name your data factory (must be globally unique)
- Choose the pricing tier: Data Factory (free) or Data Factory v2 (standard)
- Enable Git integration for version control (recommended for teams)
The studio interface includes four main areas: Author, Monitor, Manage, and Copy Data. We’ll focus on “Author” for pipeline creation.
Step 2: Define Linked Services
In the “Manage” tab, create linked services for your source and destination. For this example:
- Create a linked service for Azure Blob Storage using your storage account key
- Create a linked service for Azure SQL Database using SQL authentication or managed identity
Test the connections to ensure they work before proceeding.
Step 3: Create Datasets and Configure the Copy Activity
Switch to the “Author” tab and create datasets for both the source (Blob Storage) and destination (SQL Database). Specify the container, folder path, and file format (e.g., CSV or JSON). Then, create a new pipeline and drag the “Copy Data” activity onto the canvas.
- Set the source dataset in the Copy Activity settings
- Set the sink (destination) dataset
- Configure mapping options if column names differ
You can preview data directly in the interface to validate structure and content.
Step 4: Trigger and Monitor the Pipeline
Save and publish your pipeline. Then, trigger it manually using the “Debug” button. Once running, switch to the “Monitor” tab to view execution status, duration, and any errors.
“Monitoring is key—always check pipeline runs for warnings or failures, especially in production environments.” — Azure Best Practices Guide
If successful, verify that the data appears in your SQL database. You can then schedule the pipeline using a trigger (e.g., every night at 2 AM) or set up event-based triggers.
Advanced Features of Azure Data Factory
Beyond basic data movement, Azure Data Factory offers advanced capabilities that empower data engineers to build sophisticated, intelligent pipelines.
Data Flow Transformations
Azure Data Factory’s data flows provide a code-free way to perform complex transformations using a visual interface. Under the hood, they use Azure Databricks clusters to execute transformations on Spark engines.
- Support for derived columns, aggregates, pivots, and unpivots
- Conditional splits and joins across multiple datasets
- Support for custom SQL scripts and expressions
For example, you can clean customer data by removing duplicates, standardizing phone numbers, and enriching records with geolocation data—all without writing a single line of code.
Control Flow and Logic Apps Integration
Azure Data Factory supports advanced control flow patterns like if-conditions, switch cases, foreach loops, and until loops. These allow dynamic decision-making within pipelines based on runtime values.
- Use Lookup activities to retrieve configuration values from a database
- Implement error handling with Try-Catch patterns using conditional logic
- Integrate with Azure Logic Apps to send email alerts on failure
This level of orchestration makes ADF suitable for enterprise-grade workflows that require branching logic and exception handling.
Custom Activities Using Azure Functions or Databricks
When built-in activities aren’t enough, you can extend ADF with custom logic using Azure Functions, HDInsight, or Databricks. For instance, you might use an Azure Function to validate data quality or call an external API to enrich customer records.
- Pass parameters from ADF to external services
- Capture return values and use them in downstream activities
- Leverage serverless compute for lightweight, event-driven tasks
This extensibility ensures that Azure Data Factory can adapt to virtually any business requirement.
Security and Governance in Azure Data Factory
Security is paramount when dealing with sensitive data. Azure Data Factory provides robust mechanisms to ensure data privacy, compliance, and access control.
Role-Based Access Control (RBAC)
Azure Data Factory integrates with Azure Active Directory (AAD) to enforce role-based access. You can assign roles like Data Factory Contributor, Reader, or Owner at the resource group or factory level.
- Contributors can create and edit pipelines
- Readers can view but not modify resources
- Custom roles can be defined for granular permissions
This ensures that only authorized personnel can make changes to critical data workflows.
Data Encryption and Compliance
All data in transit and at rest is encrypted by default. ADF supports TLS 1.2+ for secure data transfer and integrates with Azure Key Vault for managing secrets like connection strings and API keys.
- Complies with GDPR, HIPAA, SOC 2, and other regulatory standards
- Supports private endpoints to restrict network access
- Enables auditing via Azure Monitor logs
Organizations in regulated industries such as healthcare and finance rely on these features to meet compliance requirements.
Monitoring and Alerting
The “Monitor” tab in ADF provides real-time visibility into pipeline executions, including success rates, durations, and error details. You can set up alerts using Azure Monitor to notify teams via email, SMS, or Slack when pipelines fail.
- Create dashboards to track SLA compliance
- Analyze historical trends to optimize performance
- Use Log Analytics to query execution logs programmatically
“Visibility into pipeline health is critical for maintaining data reliability and trust.” — Enterprise Data Governance Whitepaper
Real-World Use Cases of Azure Data Factory
Azure Data Factory isn’t just a theoretical tool—it’s being used by organizations worldwide to solve real business problems. Let’s explore some practical applications.
Enterprise Data Warehousing
Many companies use ADF to populate their data warehouses with data from operational systems. For example, a retail chain might use ADF to extract sales data from point-of-sale systems, transform it into a star schema, and load it into Azure Synapse Analytics for reporting.
- Handles large volumes of historical and real-time data
- Supports slowly changing dimensions (SCD) Type 2 logic
- Enables near-real-time analytics with incremental loads
This use case improves decision-making by providing up-to-date insights into customer behavior and inventory levels.
IoT Data Ingestion
In manufacturing and logistics, IoT devices generate massive streams of sensor data. Azure Data Factory can ingest this data from Event Hubs or IoT Hub, process it in batches, and store it in data lakes for predictive maintenance models.
- Processes telemetry data from thousands of devices
- Filters and aggregates data before loading
- Triggers machine learning pipelines upon data arrival
One automotive company reduced downtime by 30% by using ADF to feed sensor data into anomaly detection models.
Migration to the Cloud
Organizations undergoing digital transformation often use ADF to migrate legacy data systems to the cloud. For instance, a bank might use ADF to move customer records from an on-premises Oracle database to Azure Cosmos DB.
- Minimizes downtime with incremental sync strategies
- Validates data consistency post-migration
- Automates the entire migration workflow
This accelerates cloud adoption while ensuring data integrity throughout the process.
What is Azure Data Factory used for?
Azure Data Factory is used for orchestrating and automating data movement and transformation workflows in the cloud. It enables ETL/ELT processes, integrates data from disparate sources, and supports hybrid and multi-cloud scenarios. Common use cases include data warehousing, real-time analytics, and cloud migration.
Is Azure Data Factory a coding tool?
No, Azure Data Factory is not primarily a coding tool. While it supports code-based development (e.g., using JSON, ARM templates, or Python SDKs), it’s designed for low-code or no-code pipeline creation using a visual interface. However, developers can extend functionality with custom scripts or integrate with code repositories via Git.
How does Azure Data Factory differ from SSIS?
Azure Data Factory is the cloud-native successor to SQL Server Integration Services (SSIS). While SSIS runs on-premises and requires server management, ADF is serverless, scalable, and built for cloud and hybrid scenarios. ADF also offers better integration with modern data platforms like Databricks and Synapse.
Can Azure Data Factory handle real-time data?
Yes, Azure Data Factory supports near-real-time data processing through event-based triggers (e.g., when a new file arrives in Blob Storage) and integration with Azure Event Hubs and Stream Analytics. While it’s optimized for batch processing, it can support streaming scenarios with proper design.
Is Azure Data Factory free to use?
Azure Data Factory offers a free tier with limited execution minutes per month. Beyond that, it operates on a pay-per-use pricing model based on pipeline activity runs, data movement, and data flow execution. There are no upfront costs, making it cost-effective for small to large-scale operations.
In conclusion, Azure Data Factory is a powerful, flexible, and secure platform for modern data integration. From simple data movement to complex orchestration of hybrid workflows, it empowers organizations to unlock the value of their data. Whether you’re migrating to the cloud, building a data warehouse, or enabling real-time analytics, ADF provides the tools you need to succeed. With its deep integration into the Azure ecosystem, serverless architecture, and support for both code-free and code-centric development, it stands out as a leader in cloud data integration. As data continues to grow in volume and complexity, Azure Data Factory will remain a critical component of any enterprise data strategy.
Recommended for you 👇
Further Reading: